...
In den letzten 15 Monaten habe ich versucht, unsere Spieledatenbank nach den Prinzipien des Domain Driven Design (DDD) neu zu durchdenken. Kurz gesagt konzentriert man sich dabei auf fachliche Kernbereiche oder Kontexte (DDD: "Bounded Contexts") der geplanten Anwendung, diese . Diese sind dann bei der Umsetzung relativ lose untereinander gekoppelt, so dass jeder einzelne Kontexte Kontext die eigene Fach-Logik komplett selber und relativ unabhängig umsetzen kann. Das macht die sinnvolle und effiziente Entwicklung von großen, komplexen Anwendungen überhaupt erst langfristig möglich. Für Oregami habe ich einige dieser Kontexte identifiziert und die groben Beziehungen untereinander in einer sog. "Context Map" dargestellt: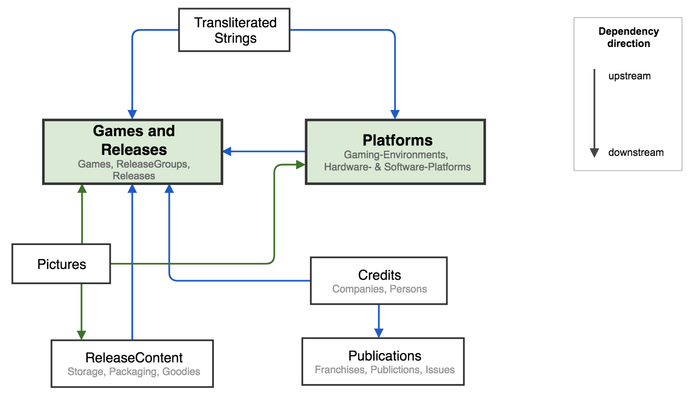
Wie im letzten technischen Blog-Post beschrieben hatte ich mir zur technischen Umsetzung ebenfalls viele Gedanken gemacht und wollte mich dabei auf Dinge wie "Event Sourcing" (https://de.wikipedia.org/wiki/Event_Sourcing) und "CQRS" (https://de.wikipedia.org/wiki/Command-Query-Responsibility-Segregation) stützen. Genau das habe ich auch getan, und die Ergebnisse der ersten Programmierungen sind meiner Ansicht nach sehr vielversprechend. Doch dazu später mehr.
Eine sehr große Hilfe bei den bisherigen Arbeiten is ist das Axonframework (http://www.axonframework.org/). Es unterstützt eben genau bei den Themen "Event Sourcing" und "CQRS", so dass man sich nahezu vollständig auf die Programmierung der fachlichen Dinge konzentrieren kann. Auch wenn so ein umfangreiches Framework natürlich vor dem Einsatz einiges an Einarbeitung erforderteerfordert, was auch mit einer der Gründe ist, weshalb ich so lange nichts von mir habe hören lassen ![]() . Mittlerweile konnte ich aber einige Muster erarbeiten, die ich dann in der Zukunft immer wieder einsetzen werde.
. Mittlerweile konnte ich aber einige Muster erarbeiten, die ich dann in der Zukunft immer wieder einsetzen werde.
Als den Bereich, in dem wir als erstes Daten erfassen wollen, haben wie die Spieleplattformen ausgewählt (englisch für uns "Platforms" oder "Gaming Environments"). Wenn man Informationen über Spieleplattformen vernünftig erfassen und speichern möchte, kommt man ziemlich zu schnell zu dem Thema "Internationalisierung der Plattform-Bezeichnungen". Hier wenden wir unsere Diskussionsergebnisse aus dem Bereich der Spiele-Titel an, die wir umfassend in diesem einem Blogbeitrag (https://www.oregami.org/blog/ende/2017/thoughtsgedanken-aboutzur-internationalizationinternationalisierung-i18n) beschrieben haben. Da wir das Erfassen von Bezeichnungen an mehreren Stellen im System benötigen werden und es eine wichtige Rolle in der Oregami-Datenwelt spielt, haben wir es zu einem eigenen Kontext befördert, den wir fortan "Transliterated Strings" nennen. Während dieser Kontext selber für den Benutzer unserer Datenbank später nicht als einzelner, separat angebotener Bereich (z.B. in der Webseiten-Navigation) auftauchen wird, so werden seine Funktionen und Daten doch mehrfach innerhalb der anderen, öffentlichkeitswirksameren Bereiche verwendet werden. Innerhalb dieses Kontextes wird es z.B. möglich sein, zu jedem erfassten Titel (gilt auch für Spiele-Titel) Übersetzungen zu hinterlegen.
In der aktuellen Entwicklungs-Version unserer Web-Anwendung habe ich erst einmal versucht, die beiden Kontexte "Platforms" und "TransliteratedStrings" zusammenzubringen. Denn darin wird zukünftig genau die Kunst bestehen: das Integrieren mehrerer Kontexte elegant zu lösen. Konkrete bedeutet das für uns: Bezeichnungen werden als "transliterierte Texte" (https://de.wiktionary.org/wiki/transliterieren) im entsprechenden Kontext erfasst, und der Plattformen-Kontext verweist an den richtigen Stellen auf die transliterierten Texte.
...
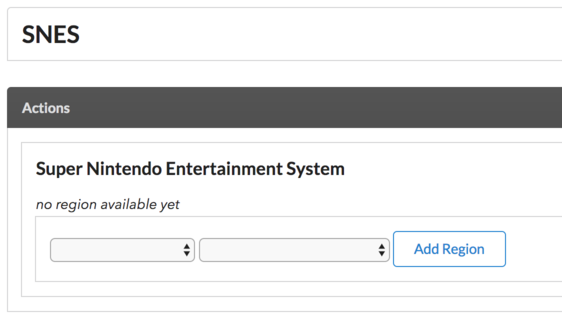
Nun liegt also eine Plattform mit einem transliterierten Titel vor. Für diesen Titel kann man noch ergänzen, in welcher Region er in welcher Art und Weise verwendet wurde, also z.B. ist "Super Nintendo Entertainment System" ein Original-Titel in Europa:
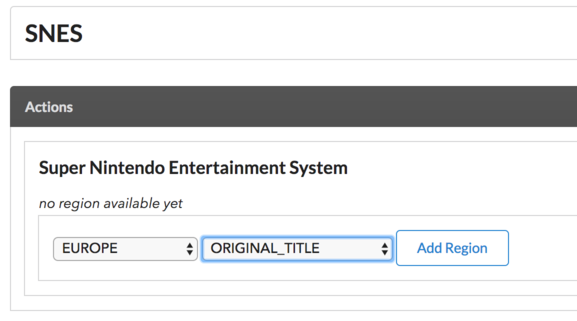
Noch Nach zwei weitere weiteren internationalisierte Titel sieht es dann so aus:
...
Bei Oregami legen wir großen Wert auf die Qualität der abgelegten Informationen. Diese hohe Qualität wollen wir u.Aa. dadurch erreichen, dass an möglichst viele Stellen bei Dateneingaben eine Quelle angegeben werden muss: woher können wir sonst sicher sein, dass diese Daten tatsächlich der Realität entsprechen? Außerdem sollte es in unserem System später möglich sein, Dateneingaben innerhalb eines Überprüfungsprozesses zu validieren und in irgendeiner Art und Weise als "geprüft" zu markieren. Das Abspeichern jeder Eingabe über die in den daraus entstandenen Events werden uns genau diese Dinge ermöglichen. Quellenangaben wird man und z.B. den Events zuordnen können. Nach einer Überprüfung der Events werden wir die anzuzeigenden Daten zielgerichtet aktualisieren können, da wir diese wir nach dem CQRS-Prinzip komplett getrennt von den Events speichern. Es ist sogar möglich, mehrere sog. "Read models" anzulegen, so dass z.B. Prüfer den letzten neuesten Stand inkl. aller ungeprüften Events einsehen können, während für die Öffentlichkeit nur überprüfte Daten sichtbar sein werden. Diese Dinge sind momentan noch Zukunftsmusik, aber mit dem aktuellen Entwicklungsstand haben wir die Basis dafür geschaffen.
...