Developer diary September 2018
- Sebastian Eichholz
- Jens Mildner
It's been more than a year since my last blog post about developing our open game database. But that doesn't mean I haven't made any progress. Therefore I would like to report to you today once again about the current state of development.
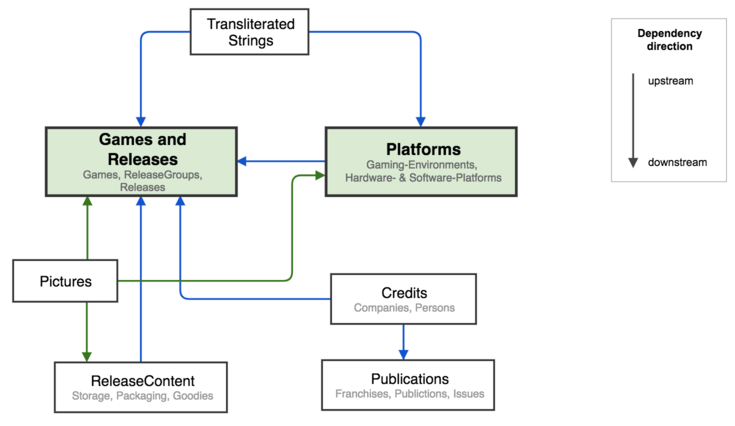
In the last 15 months I have tried to rethink our game database according to the principles of Domain Driven Design (DDD). In short, the focus is on core areas or contexts (DDD: "bounded contexts") of the planned application. These are then loosely coupled to each other during implementation, so that each individual context can implement its own subject logic independently. This is what makes the sensible and efficient development of large, complex applications possible in the long term. For Oregami I identified some of these contexts and presented the rough relationships among them in a so-called "context map":
As described in the last technical blog post I had also thought a lot about the technical implementation and wanted to rely on things like "Event Sourcing" (https://martinfowler.com/eaaDev/EventSourcing.html) and "CQRS" (https://martinfowler.com/bliki/CQRS.html). That is exactly what I have done, and I think the results of the initial programming are very promising. But more about this later.
The Axon Framework (http://www.axonframework.org/) is a great help in the work so far. It supports exactly the topics "Event Sourcing" and "CQRS", so that one can concentrate almost completely on the programming of the important things about games. Even if such an extensive framework naturally requires some training before use - which is one of the reasons why you haven't heard anything from myself for so long (smile) - I was able to work out some patterns that I will use again and again in the future meanwhile.
As the first area in which we want to collect data, we have selected "Platforms" or "Gaming Environments" for us. If you want to collect and store information about gaming platforms sensibly, you will soon come to the topic "Internationalization of platform names". Here we apply our discussion results from the field of game titles, which we have described comprehensively in a blog post (https://www.oregami.org/blog/en/2017/thoughts-about-internationalization-i18n).
Since we will need to capture titles in several places in the system and it plays an important role in the Oregami data world, we have promoted it to its own context, which we will now call "Transliterated Strings". While this context itself will not appear for the user of our database as a single, separately offered area later (e.g. in the website navigation), its functions and data will nevertheless be used several times within the other, more public effective areas. Within this context, it will be possible, for example, to store translations for each title entered (also applies to game titles).
In the current development version of our web application, I first tried to combine the two contexts "Platforms" and "TransliteratedStrings". Because precisely this will be the art of the future: integrating several contexts elegantly. In practice this means that designations are recorded as "transliterated texts" (https://en.wikipedia.org/wiki/Transliteration) in the appropriate context, and the platform context refers to the transliterated texts in the right places.
The first step is to create a new platform in the system. Since all the descriptions can only be entered in great detail later, only one working title is specified for the initial creation.
<Bild>
The working title is no longer required later - if real names have been entered. It is clear that the user has to click through several steps to add a title - these are the side effects of dividing the subject logic into two separate contexts. From a technical point of view, the path could look like this:
<Bild>
Why does the system search for existing descriptions after entering the desired title? If the same name already exists, it should be reused. If not, the name is created.
From the user's point of view, this is how a title is added:
<Bilder>
Now we have a platform with a transliterated title. For this title you can add in which region it was used to which purpose, e.g. "Super Nintendo Entertainment System" is an original title in Europe:
<Bilder>
After two more internationalized titles it looks like this:
<Bild>
But we wouldn't be Oregami if that was all.
As mentioned above, we base all data input on the principle of event sourcing, i.e. every change to data is stored as an event and not "as before" directly in a database, which is also used to display the stored data. But where are the events of our data input? Here:
<Events>
A closer look at these data reveals the following event names:
- GamingEnvironmentCreatedEvent
- TitleAddedEvent
- TitleUsageAddedEvent
- no. 2 and 3 are repeated for each title>
Each of these events contains all the data needed to derive the final state of the platform. This is exactly the principle of event sourcing. But why are we making all this effort? Why don't we simply update the previous data directly with the new data entered by the user?
At Oregami we attach great importance to the quality of the information we store. One of the ways we want to achieve this high quality is by having to specify a source for as many things as possible when entering data: how else can we be sure that this data actually correspond to reality? In addition, it should later be possible in our system to validate data entries within a verification process and to mark them as "verified" in some way.
Saving each entry in the resulting events will enable us to do just that. Sources can be assigned to events, for example. After checking the events, we will be able to update the data to be displayed in a targeted manner, as we store them completely separated from the events according to the CQRS principle. It is even possible to create several so-called "read models", so that e.g. auditors can see the latest status including all unchecked events, while only checked data will be visible to the public. These things are still dreams of the future, but with the current state of development we have created the basis for it.
The current status can be tested at https://dev.oregami.org (Login: User=user1, Password=password1). However, the data will not be stored for a long time, after each program change they will be lost again. Furthermore, the stored data model still needs to be extended: as described in detail in this article (https://www.oregami.org/blog/en/2015/sorting-out-platform-mess), our game platforms consist of hardware and software platforms, which is currently not yet supported. But based on the current status I could try out, learn and implement many important things.